There exist many schemes for Sanskrit transliteration. For instance, there is a Harvard-Kyoto scheme, which is easier to type, but harder to read, and there is an International Alphabet of Sanskrit Transliteration (IAST), which is harder to type, but easier to read. However, these schemes only provide transliteration methods using the Latin script (either plain Latin characters or Latin characters with diacritics) and do not cover transliteration into other scripts like Cyrillic. The task of Cyrillic transliteration is not new and, in this blog post, we explore the available methods of Sanskrit transliteration into Russian - those used in practice and the one chosen for Chakra Darshana and our online Sanskrit transliteration tool.
Nowadays, Sanskrit transliteration into multiple languages is most prominently featured in the books published by the Bhaktivedanta Book Trust, which is the world’s largest publisher of classic Vaiṣṇava texts and contemporary works on bhakti yoga, most notably those by His Divine Grace A. C. Bhaktivedanta Swami Prabhupada, the founder-ācārya of the International Society for Krishna Consciousness (ISKCON). For classic Sanskrit texts, these books usually contain the original Sanskrit verse in Devanagari, a transliteration of the verse, a word for word translation, a literary translation, and a purport. In English books, the transliteration scheme is mostly identical with IAST, except that ṁ (with dot above) is used instead of ṃ (with dot below).
In Russian books, the transliteration scheme is similar and is based on the same general principle. It augments the basic Russian characters with the same diacritical marks (except that plain ш is used for ṣ), prettifying some cases to be consistent with the general rules of the Russian language, like transliterating eṣaḥ (he) as эшах̣ instead of ешах̣.
This gives the following transliteration table (if it does not render properly, this might be a font issue, read below; also, for the purposes of this blog post, the table uses м̣ instead of м̇, because currently Chakra Darshana follows IAST, but that may change in the future; finally, compare with English table):
| Sanskrit letters | |||||
|---|---|---|---|---|---|
| а | а̄ | и | ӣ | у | ӯ |
| р̣ | р̣̄ | л̣ | л̣̄ | ||
| е/э | аи | о | ау | ||
| м̣ | х̣ | ||||
| ка | кха | га | гха | н̇а | |
| ча | чха | джа | джха | н̃а | |
| т̣а | т̣ха | д̣а | д̣ха | н̣а | |
| та | тха | да | дха | на | |
| па | пха | ба | бха | ма | |
| йа | ра | ла | ва | ||
| ш́а | ша | са | |||
| ха | |||||
So far it looks similar to and just as easy as with English, but there is a problem. Namely, the
Unicode computing industry standard, which is meant to provide characters from
most of the world’s writing systems, contains characters with diacritics that are needed for the English version of
IAST, but it does not have most of the characters needed for the Russian version. In fact, in only has two (see the
Cyrillic character range): Ӣ (U+04E2) and ӣ (U+04E3), and Ӯ
(U+04EE) and ӯ (U+04EF). Other characters do not have a direct representation in Unicode, which means that they
are not included into general-purpose fonts.
There are two ways to approach this problem. The first approach is to design a custom font with custom code points that includes the necessary glyphs. For instance, the online Bhaktivedanta VedaBase uses exactly this approach. Let’s take Bhagavad-gītā 9.25 as an example:

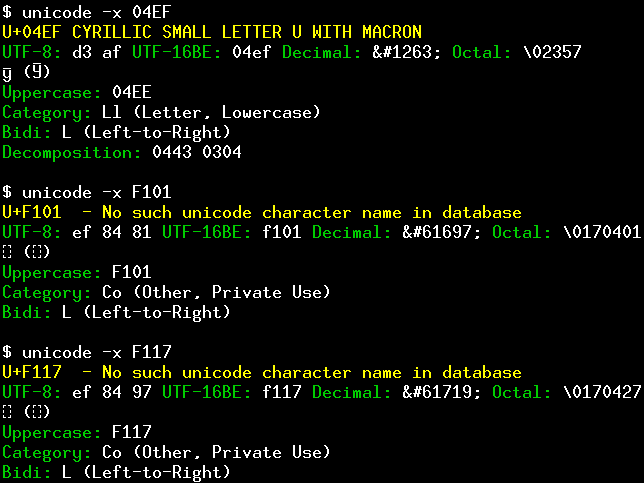
Looking at the character codes used in this verse, we will see that it uses U+04EF for ӯ (as expected), U+F101 for
а̄, and U+F117 for р̣̄. If we ask the unicode program what these code points correspond to, it will confirm that
only the first of them belongs to Unicode:
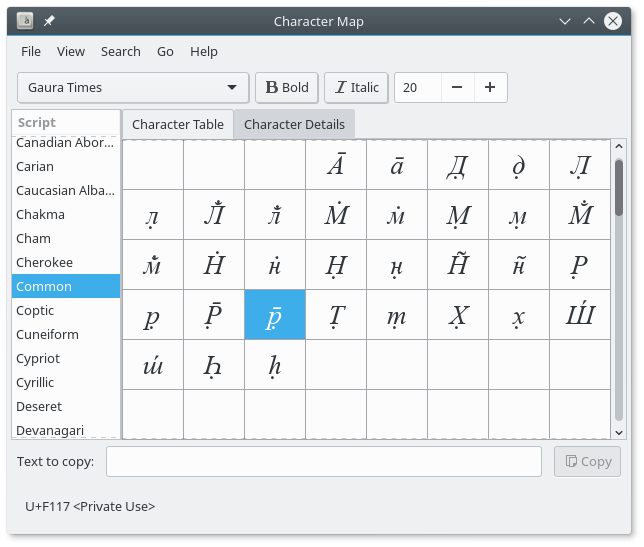
The Bhaktivedanta VedaBase in the verse above uses a Gaura Times font.
Inspecting it with gucharmap (GNOME Character Map) and
gnome-font-viewer confirms that is has custom glyphs designed specifically for the purpose:
For the purposes of Chakra Darshana, which includes a Russian translation since version 1.5.0, we felt that designing a custom font and bundling it with the application would be a bit too much at this point. Fortunately, there exists a second approach to solving the problem using combining diacritical marks.
Combining diacritical marks allow to take a base character and add some diacritics to it. For instance, the character
а̄ would be represented as the base character а (U+0430), immediately followed by a combining macron (U+0304).
This way, а̄ actually consists of two characters and four bytes in total. Some characters, like р̣̄ in the verse, need
two combining marks: the base character р (U+0440), the combining dot below (U+0323), and the combining macron
(U+0304). The resulting р̣̄ thus consists of three characters and six bytes.
This is a nice universal solution, because it does not require a custom font and may work with any font. At the same time, there is no guarantee that it will render in a pretty way with any given font and a rendering engine. Currently, it seems to work sufficiently well in practice.
![]()
Now that we understand the theory, we need a practical way to type these characters. As always, Vim comes to the rescue! Unlike the English transliteration covered earlier, we cannot use digraphs here, because digraphs map to a single character only, but Vim fully supports combining characters and we can use insert mode mappings to make the editing process similar to that of English.
Here is the updated sanskrit.vim script that we use for development and it includes the necessary settings for both
English and Russian transliteration:
" digraph A- 256 " Ā
" digraph a- 257 " ā
" digraph I- 298 " Ī
" digraph i- 299 " ī
" digraph U- 362 " Ū
" digraph u- 363 " ū
" digraph M. 7744 " Ṁ
" digraph m. 7745 " ṁ
" digraph N. 7748 " Ṅ
" digraph n. 7749 " ṅ
" digraph N? 209 " Ñ
" digraph n? 241 " ñ
" digraph S' 346 " Ś
" digraph s' 347 " ś
digraph R, 7770 " Ṛ
digraph r, 7771 " ṛ
digraph R- 7772 " Ṝ
digraph r- 7773 " ṝ
digraph L, 7734 " Ḷ
digraph l, 7735 " ḷ
digraph L- 7736 " Ḹ
digraph l- 7737 " ḹ
digraph M, 7746 " Ṃ
digraph m, 7747 " ṃ
digraph H, 7716 " Ḥ
digraph h, 7717 " ḥ
digraph T, 7788 " Ṭ
digraph t, 7789 " ṭ
digraph D, 7692 " Ḍ
digraph d, 7693 " ḍ
digraph N, 7750 " Ṇ
digraph n, 7751 " ṇ
digraph S, 7778 " Ṣ
digraph s, 7779 " ṣ
imap <C-k>А- А̄
imap <C-k>а- а̄
imap <C-k>И- Ӣ
imap <C-k>и- ӣ
imap <C-k>У- Ӯ
imap <C-k>у- ӯ
imap <C-k>Мю М̇
imap <C-k>мю м̇
imap <C-k>Ню Н̇
imap <C-k>ню н̇
imap <C-k>Н, Н̃
imap <C-k>н, н̃
imap <C-k>Шэ Ш́
imap <C-k>шэ ш́
imap <C-k>Рб Р̣
imap <C-k>рб р̣
imap <C-k>Р- Р̣̄
imap <C-k>р- р̣̄
imap <C-k>Лб Л̣
imap <C-k>лб л̣
imap <C-k>Л- Л̣̄
imap <C-k>л- л̣̄
imap <C-k>Мб М̣
imap <C-k>мб м̣
imap <C-k>Хб Х̣
imap <C-k>хб х̣
imap <C-k>Тб Т̣
imap <C-k>тб т̣
imap <C-k>Дб Д̣
imap <C-k>дб д̣
imap <C-k>Нб Н̣
imap <C-k>нб н̣Russian mappings are designed so that they are similar to type as English digraphs, even if it is not immediately apparent from the Vim script above. For example, to obtain ṃ in English we use Ctrl + K m , and to obtain м̣ in Russian we use Ctrl + K м б, which is convenient, because English , and Russian б are the same keyboard key. Similarly, to obtain ś in English we use Ctrl + K s ' and to obtain ш́ in Russian we use Ctrl + K ш э, where English ' and Russian э are the same keyboard key.
Happy Vimming!